
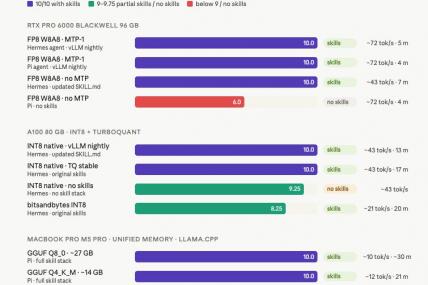
Benchmarks with the quality result
Same model, six hardware configs, with skills on = 10/10 every time.
I didn’t improve the model, just improved the instructions.
I ran the same agentic coding benchmark: TypeScript bug analysis, fix, and test generation across an RTX PRO 6000 Blackwell, A100 80GB and a MacBook Pro M5 Pro. In case of the hardware needs, I used four different quantization formats. The score with skills: 10/10. Every single run.
1. What does it mean for portability?
Q4_K_M on Apple Silicon unified memory. FP8 W8A8 on a Blackwell workstation GPU. INT8 on an A100. The hardware and the speed changes dramatically, but with the same skills the output quality is equal.
2. What does it mean for skills?
The same Qwen3.5-27B Distilled model scored 6.0/10 without skills and 10/10 with 3 skills. This was tested on identical hardware, same quantization, same tasks. The difference was 3 SKILL markdown files in total ~700 lines. No LLM fine-tuning, no larger model or other extra stuff.
3. What does it mean for productivity?
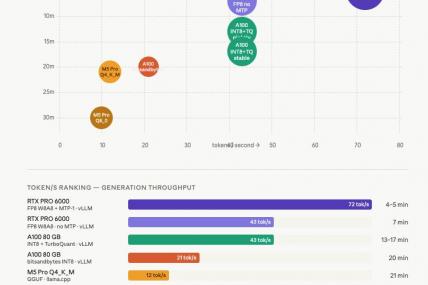
RTX PRO 6000 with FP8 and speculative decoding takes 4 minutes, 10/10. The MacBook Pro M5 with Q4_K_M takes 21 minutes, 10/10. The 7X speed gap matters for throughput, but for a single agentic coding session, both results show up as production-ready.
4. What does it mean for the model?
Alibaba distilled Claude Opus 4.6 reasoning into an open-weight 27B model. I ran it on everything from a MacBook to a Blackwell workstation, for me this is one of the best single / all-in-one model to use for agentic and coding tasks and some others.
As Mitko says always: “Have a nice weekend and own your AI”
P.S.: Looking forward to running the tests on the Gemma-4 models but currently Gemma-4 has issues with TypeScript coding.
| Benchmarks: |


| Kopfbild: |
| KI, Werkstattbericht |